- 首先,你需要用你的邮箱,主动发送 订阅 两个字到 3579137434@qq.com ,证明邮箱确实是你自己的
- 请将 wb@mail.toptopn.com 这个邮箱地址设置为重要联系人,避免邮件进入垃圾箱
- 收不到邮件有几种情况,进垃圾箱了或者进了应用黑名单
- 优先排查是否进了垃圾箱,如果不是,再把邮箱发给作者确认是否进了应用黑名单
以下是比较主流的浏览器应用中心(可以在各大应用商店搜索:网页更新提醒):
因为「墙」的存在,很多小伙伴不能愉快地访问谷歌,可以下载courier.crx后手动安装。
因为应用商店审核通常是需要时间,官网版本可以更最快体验最新的功能和BUG修复。
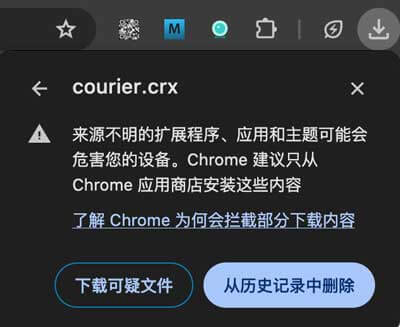
下载完成后,打开浏览器扩展管理中心(在浏览器地址栏输入如下地址):
- Chrome浏览器:chrome://extensions
- Edge浏览器:edge://extensions
- 360安全浏览器:se://extensions
- 360极速浏览器:chrome://extensions
- QQ浏览:qqbrowser://extensions
然后,需要勾选页面右上角(Edge浏览器左侧)的「开发者模式」(默认是关闭的)
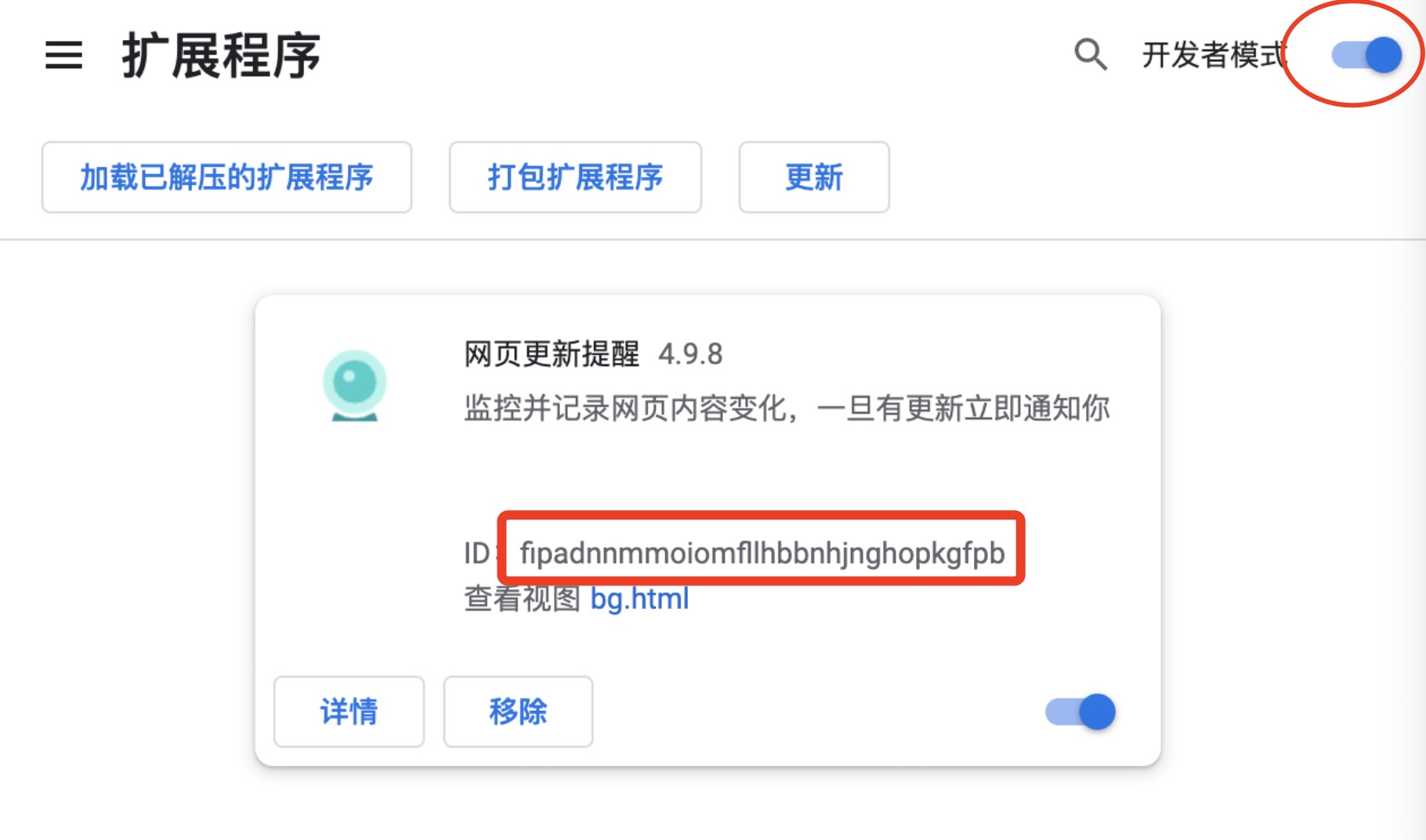
最后,把下载的courier.crx文件拖到这个页面就可以完成安装了。
注意:请认准图上这个ID,这是插件的唯一标志,如果ID跟应用商定不一致请拒绝安装
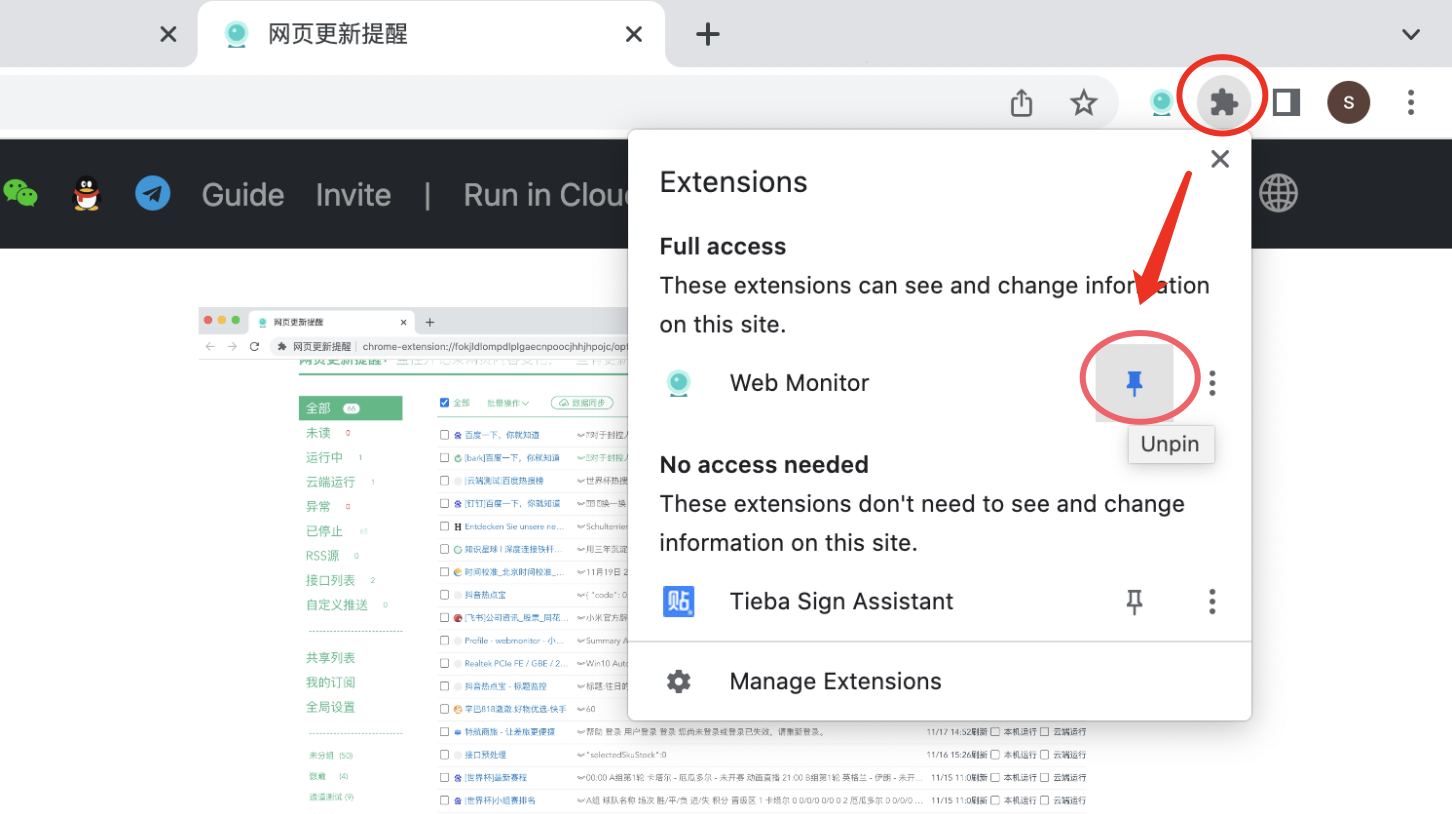
有不少小伙伴安装插件后找不到,这是因为默认是会被折叠起来的,可以选择固定在浏览器顶部插件拦,如下图所示:
安装kiwi浏览器以后,安装4.19.5版本插件,操作参考 这个视频
好在,以上这些问题都可以通过「自动模式」弥补。
如果想要提取json中的特定字段,请使用JSONPath规则,假设json数据如下:
{
"store": {
"book": [
{ "category": "reference",
"author": "Nigel Rees",
"title": "Sayings of the Century",
"price": 8.95
},
{ "category": "fiction",
"author": "Evelyn Waugh",
"title": "Sword of Honour",
"price": 12.99
},
{ "category": "fiction",
"author": "Herman Melville",
"title": "Moby Dick",
"isbn": "0-553-21311-3",
"price": 8.99
},
{ "category": "fiction",
"author": "J. R. R. Tolkien",
"title": "The Lord of the Rings",
"isbn": "0-395-19395-8",
"price": 22.99
}
],
"bicycle": {
"color": "red",
"price": 19.95
}
}
}
| JSONPath | 含义 |
|---|---|
| $.store.book[*].author | 所有store.books中的author |
| $..author | 所有author |
| $.store.* | store下的所有内容 |
| $.store..price | store下的所有price |
| $..book[2] | 3个book |
| $..book[(@.length-1)] | 最后1个book |
| $..book[-1:] | 最后1个book |
| $..book[0,1] | 前2个book |
| $..book[:2] | 前2个book |
| $..book[?(@.isbn)] | 过滤包含isbn的book |
| $..book[?(@.price<10)] | 过滤价格小于10的book |
| $..* | json中的所有内容 |
- 全局配置:对所有的检测任务生效
- 任务配置:对单个检测任务生效
- 批量配置:对多个任务的某些配置进行批量修改
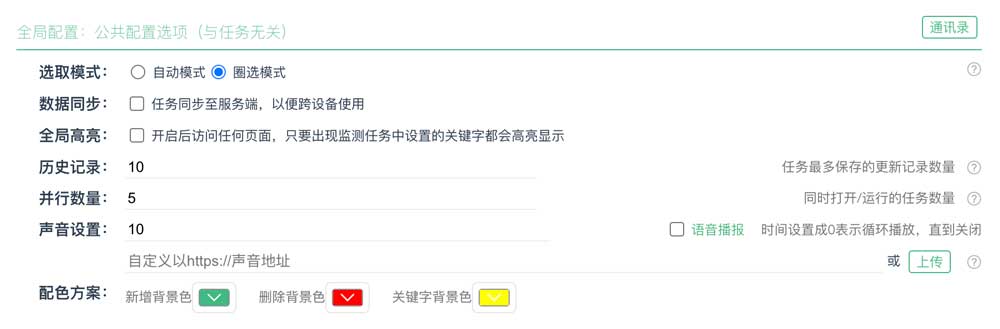
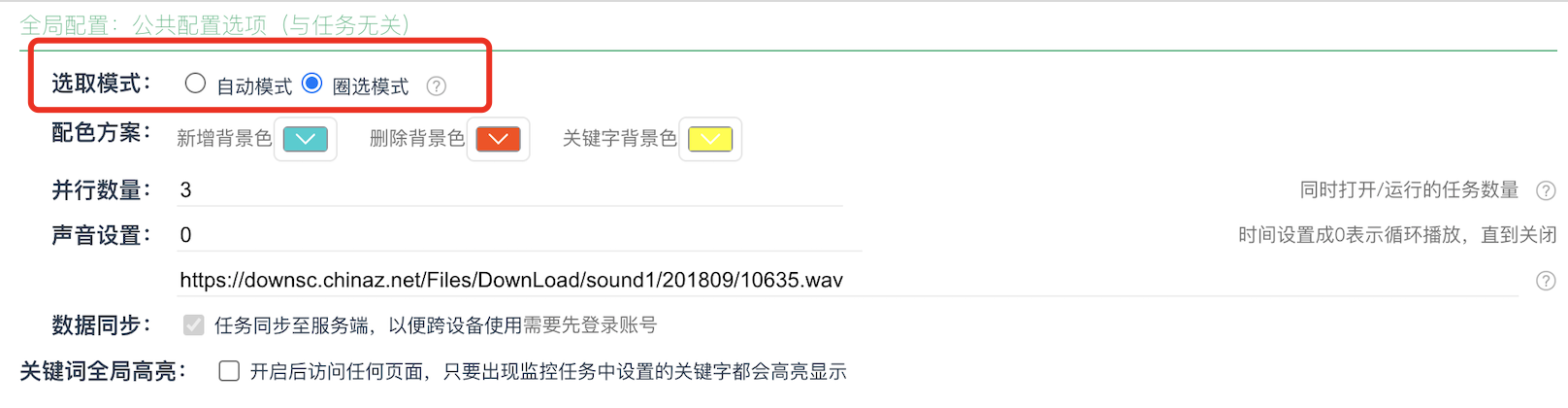
- 选取模式:具体参考「圈选模式」
- 数据同步:勾选后,将任务同步到服务器,以便在其他设备上登录的时候使用,开启后任何的增删改操作也会自动同步
- 关键词高亮:开启后浏览任何网页,一旦出现任务中存在的关键字就会高亮显示
- 历史记录:为了更好的性能,默认每个任务只保留10条历史记录,如果需要更多的记录可以自行调整
- 并行数量:浏览器可以同时检测的任务数量,任务数越大能够检测的任务量越多,浏览器的资源占用也会越高
- 声音设置:可以设置提示音的持续时间(0表示无限循环),支持线上地址(以https开头)或者上传本地音频文件,在站长素材上有很多素材
- 配色方案:可以根据自己的喜好,配置个性化的提示颜色,配置对本地显示和推送的内容都生效
-
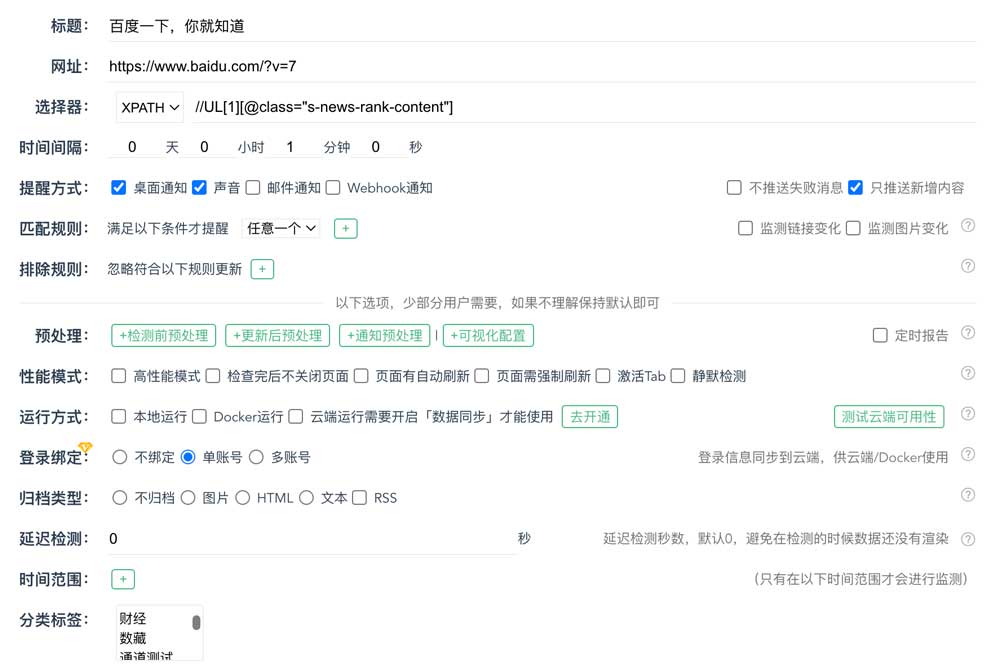
选择器:用于检测的时候提取内容,默认是不需要干预的,程序会根据圈选的区域自动生成,当然如果您懂css/xpath也可以自行修改,现在支持两种选择器,并支持多区域选择。
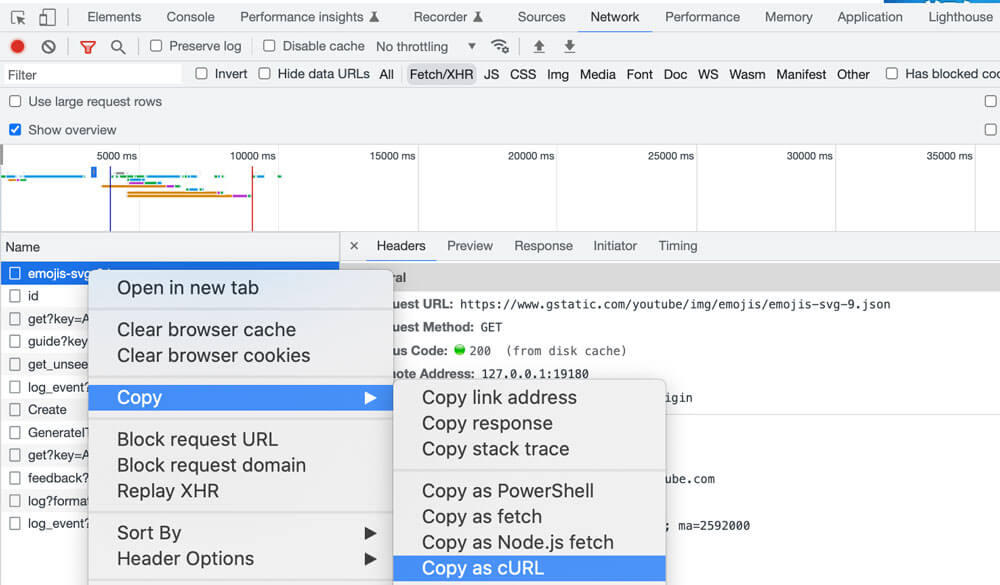
多个css选择器使用英文,隔开,多个xpath选择器用|隔开。选择器的获取方法:在浏览器页面按右键->检查打开开发者面板,然后参考如下图示操作:

注意,如果是输入类型,需要选中input或textarea标签,如果是下拉选项类型需要选中select标签,如果是点击内容需要选中button或者input标签,如果是链接要选中a标签,如果是图片需要选中img或者image标签
- 时间间隔:默认10分钟,可以根据需要修改,很多网站有频率控制,检测太频繁可能会被限制访问甚至封号,需要自定控制检测间隔
- 提醒方式:桌面通知和声音属于本地通知,邮件和webhook属于推送。部分任务因为源站的因素有时候可能会检测失败,默认是会将失败的信息推送的,可以选择不推送
- 云端运行:云端运行是指任务在服务端运行,不需要开机也能监控。此功能有很多限制,使用之前请先测试一下是否可用,这里可以查看检测结果
- 登录绑定,解决两个问题:
- 需要登录的网站,无法在云端或Docker使用的问题
- 同一个浏览器无法登录多个账号的问题
- 1. 登录账号A,将任务的网址改成url?name=A 注意如果网址本身就有?则将前面的?改成&
- 2. 然后再这个页面上完成圈选
- 3. 保存的时候,勾选「登录绑定」->「多账号」 注意:这个时候需要额外授予cookie权限
- 4. 保存以后,第一个账号就添加完成,然后退出当前账号,登录别的账号重复1-3步骤即可
- 归档类型
- 当检测到更新后,处理通知,还可以自动将更新的内容下载到本地存档
- 存档方式包括:图片/HTML(包括差异对比)、纯文本、RSS
- 存档文件名为任务标题+更新的时间
- RSS归档需要消耗存储和带宽资源,会对数量有限制,详细参考权益说明
- 延迟检测:部分网页数据是异步加载,而且加载很慢,为了防止检测失败,可以设置一个延迟检测的时间,等待数据加载完成后再检测
- 性能模式:
- 高性能模式:在检测的时候只加载页面必要的代码,不加载图片/媒体等非核心的资源,从而提高检测速度
- 检测后不关闭页面:将页面常驻在浏览器上,可以充分地利用浏览器的缓存,快速检测的目的
- 页面有自动刷新:一些页面本身就有刷新的页面,则完全不用程序刷新页面,完全省去了加载时间
- 页面需要强制刷新: 一些页面会有比较严重的缓存,经常要很久才能检测到更新,可以使用这个模式消除缓存
- 激活TAB: 有些页面在页面不可见的时候内容不渲染,导致程序无法提取到内容而失败,可以使用这个模式(每次检测的时候会在激活tab打开页面,会有一定的打扰)
- 静默模式: 检测的时候不打开标签,在后台运行,完全无打扰(不是所有的页面都支持,需要自行验证可行后再开启)
- 匹配规则:就是设置关键字,支持正则。匹配规则有两种模式:「全部」和「任意一个」,全部就是要命中全部的关键字才提醒,任意一个就是只要有一个关键字匹配就提醒
- 排除规则:排除规则只在不存在「匹配规则」的情况才有效,用于忽略那些不感兴趣的变更(比如:时间、数量等)
- 检测前预处理:在提取内容之前,可以通过
Javascript脚本进行预处理,用来准备提取的内容。使用场景如:有些需要设置查询条件然后查询才能看到数据;自动化测试等 - 通知前预处理:推送内容及格式是程序内置的,但是可以通过
Javascript脚本动态修改通知的人机通知的内容,达到个性化推送的目的
这么做的目的是为了保持任务的独立可配置性,如果都全局生效了就没有任务的个性化配置了。
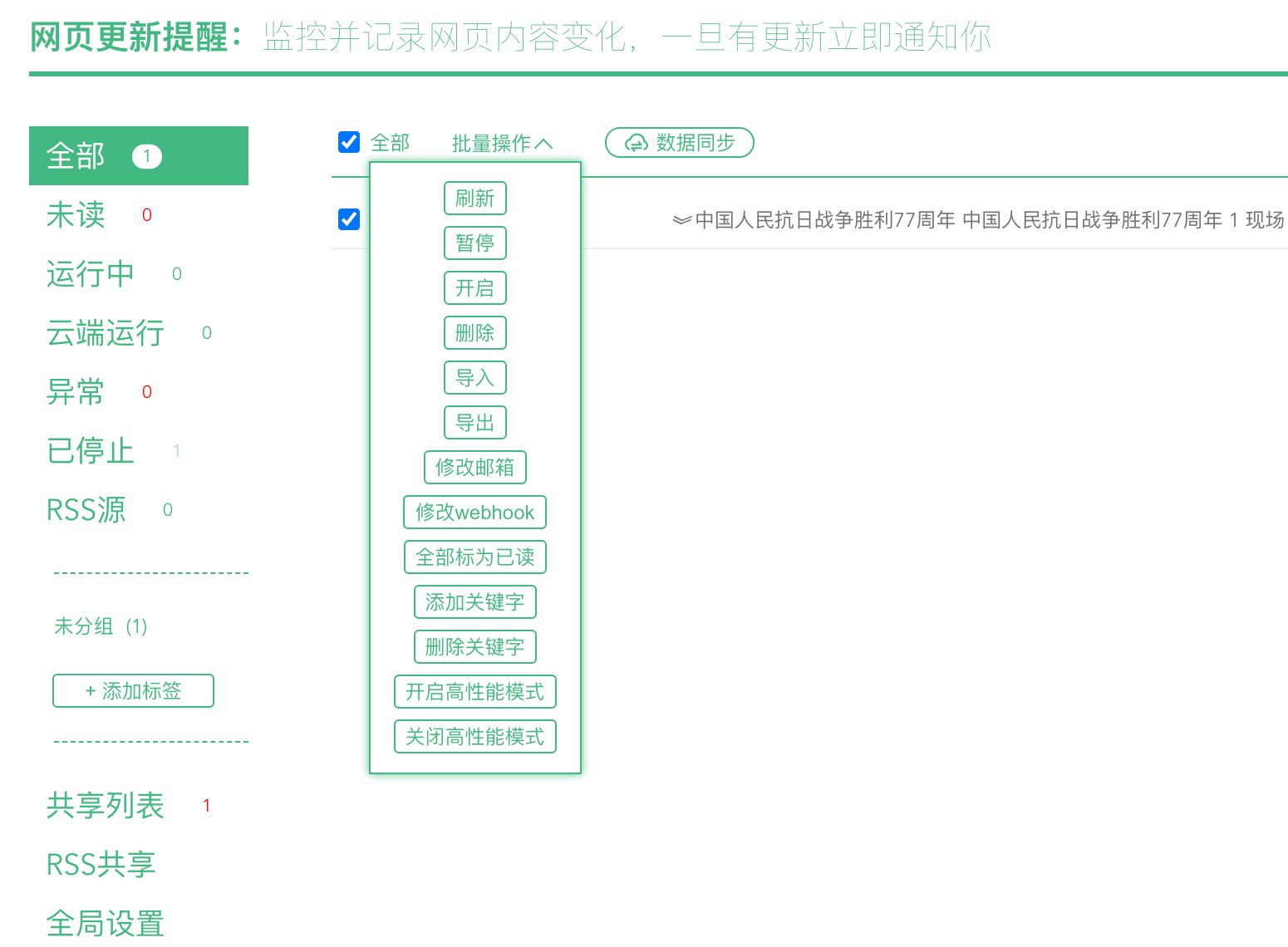
但总是有需要全局或者批量更新配置的诉求,比如:启停任务、关键增删、邮箱修改、webhook修改等。
所以,增加了批量修改的快捷按钮,在列表页的顶部,可以先勾选需要批量修改的任务,然后就可以执行批量操作了。
XPusher除了供「网页更新提醒」使用以外,还可以独立使用,一个接口就可以把消息自动推送到任意的主流信息平台。
另外,微信通道也有次数限制,但没邮件那么多的发垃圾机制,所以只要次数够用就能触达。


- 麻烦将wm@mail.suluf.com和wb@mail.toptopn.com设置为重要联系人,避免邮件再次进入垃圾箱
- 如果收不到邮件,请确认是否进入了垃圾箱(然后再找作者排查)
- 受短信模板的限制,目前仅支持发送任务标题和更新时间,且不支持繁体中文
- 短信有非常严格的过滤机制,使用前先测试一下,不要出现敏感词,避免被拦截无法收到消息
- 同一个账号每小时发送上限30条,每天上限50条,想要取消限制,请联系作者单独设置
- 钉钉获取webhook的方法,参看这里,不要勾选签名校验
- 飞书获取webhook的方法,参看这里,不要勾选签名校验
- 企业微信获取webhook的方法,参看这里
- Telegram Webhook格式:https://api.telegram.org/bottoken/sendMessage?chat_id=chat_id
- Slack Webhook格式:https://hooks.slack.com/services/xxx/yyy/zzz
- Discord Webhook格式: https://discord.com/api/webhooks/xxx
- Dodo Webhook格式:https://botopen.imdodo.com/api/v2/channel/message/send?clientid=***&token=***&channelid=***
- 其他IM获取webhook地址方法需要自行搜索
重要:钉钉机器人不要勾加签和IP地址段,勾选自定义关键词并填入:[

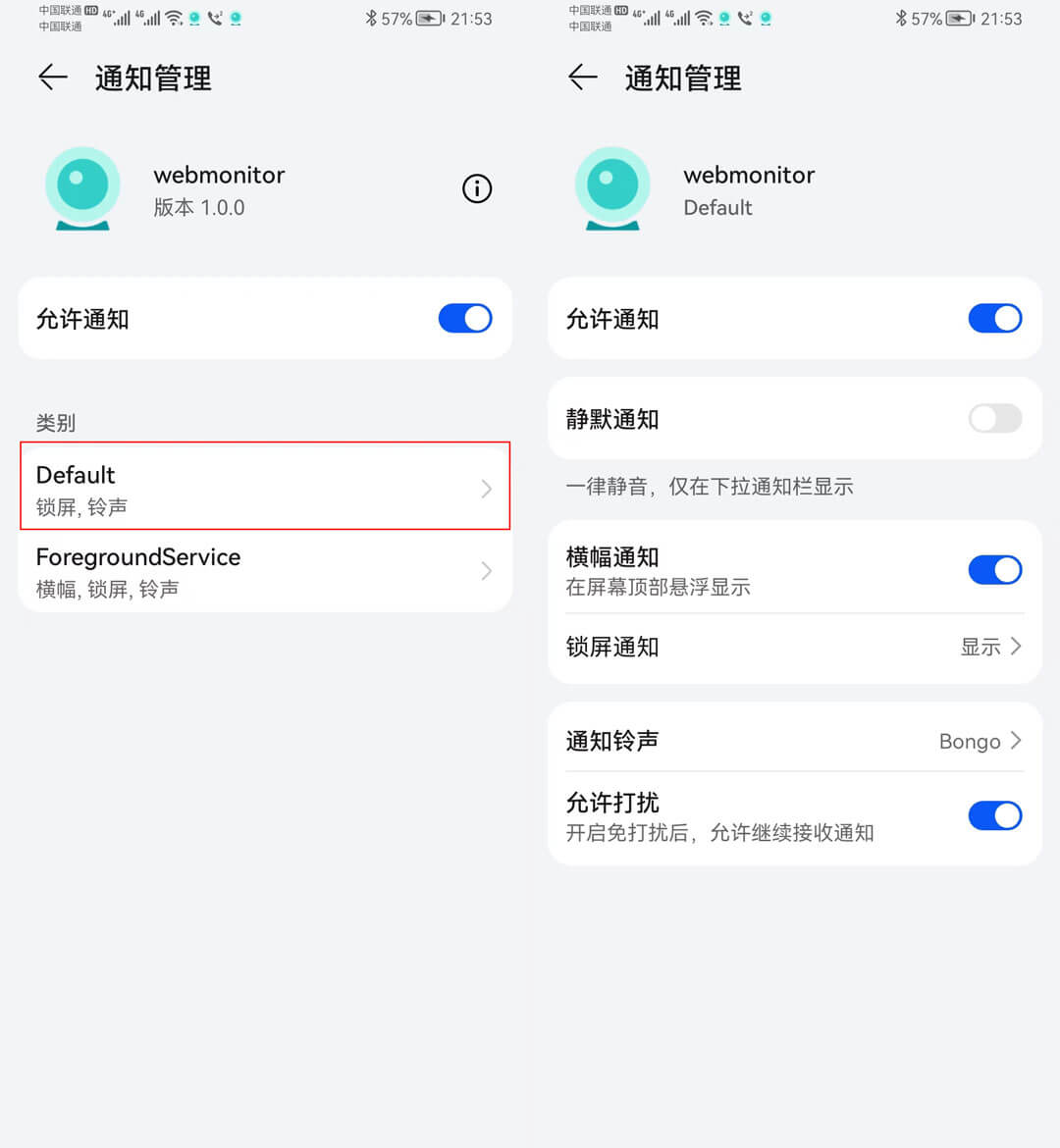

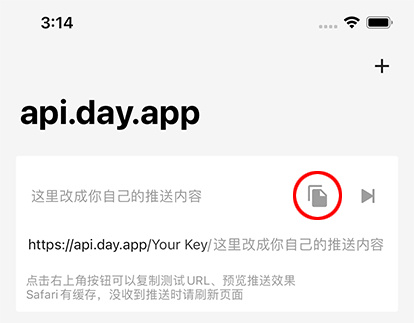
Mac系统如果有更新没有桌面通知,可以在「系统偏好设置」-> 「通知」 中打开权限: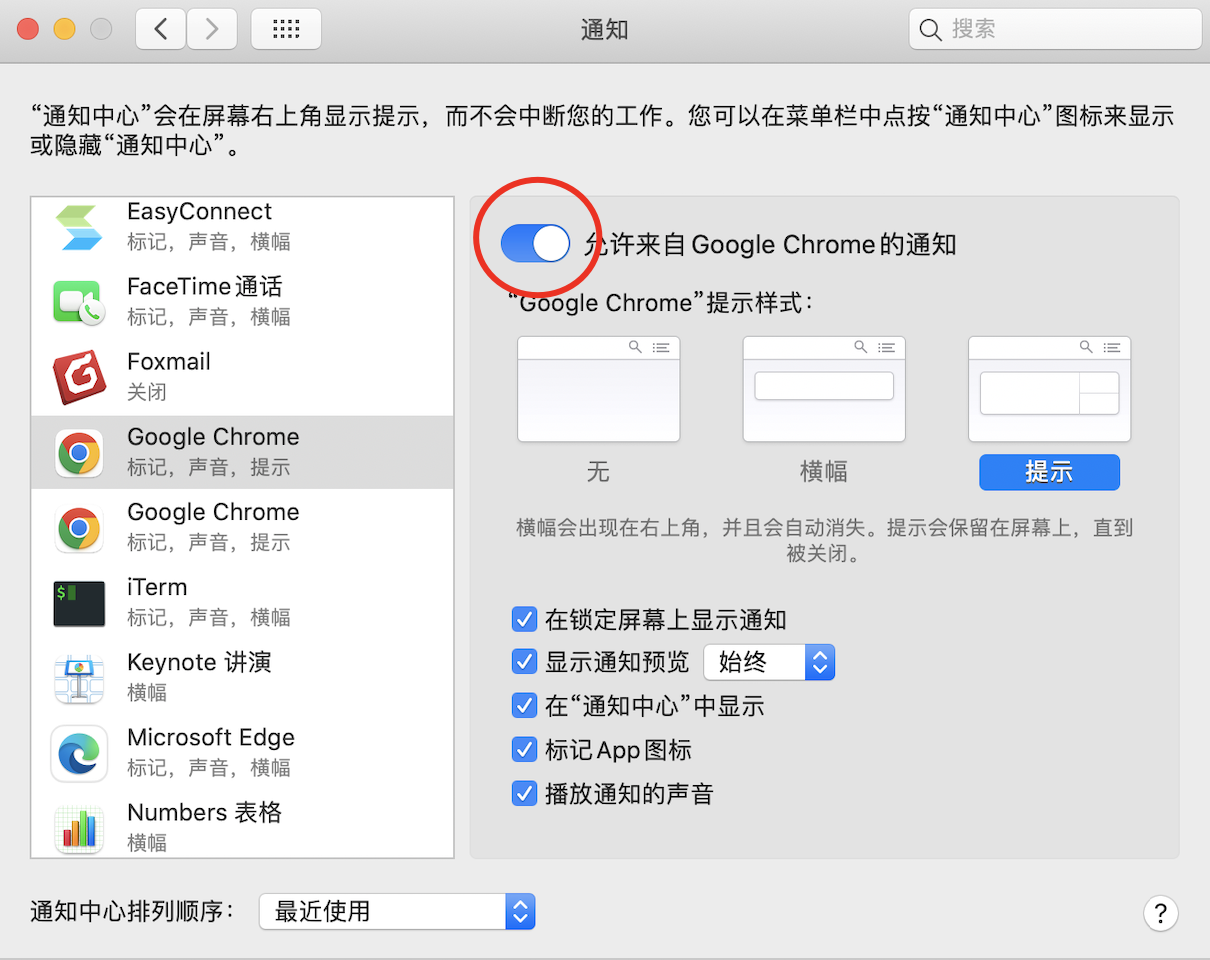
Windows系统如果有更新没有桌面通知,可以在「设置」-> 「系统」-> 「通知和操作」 中打开权限: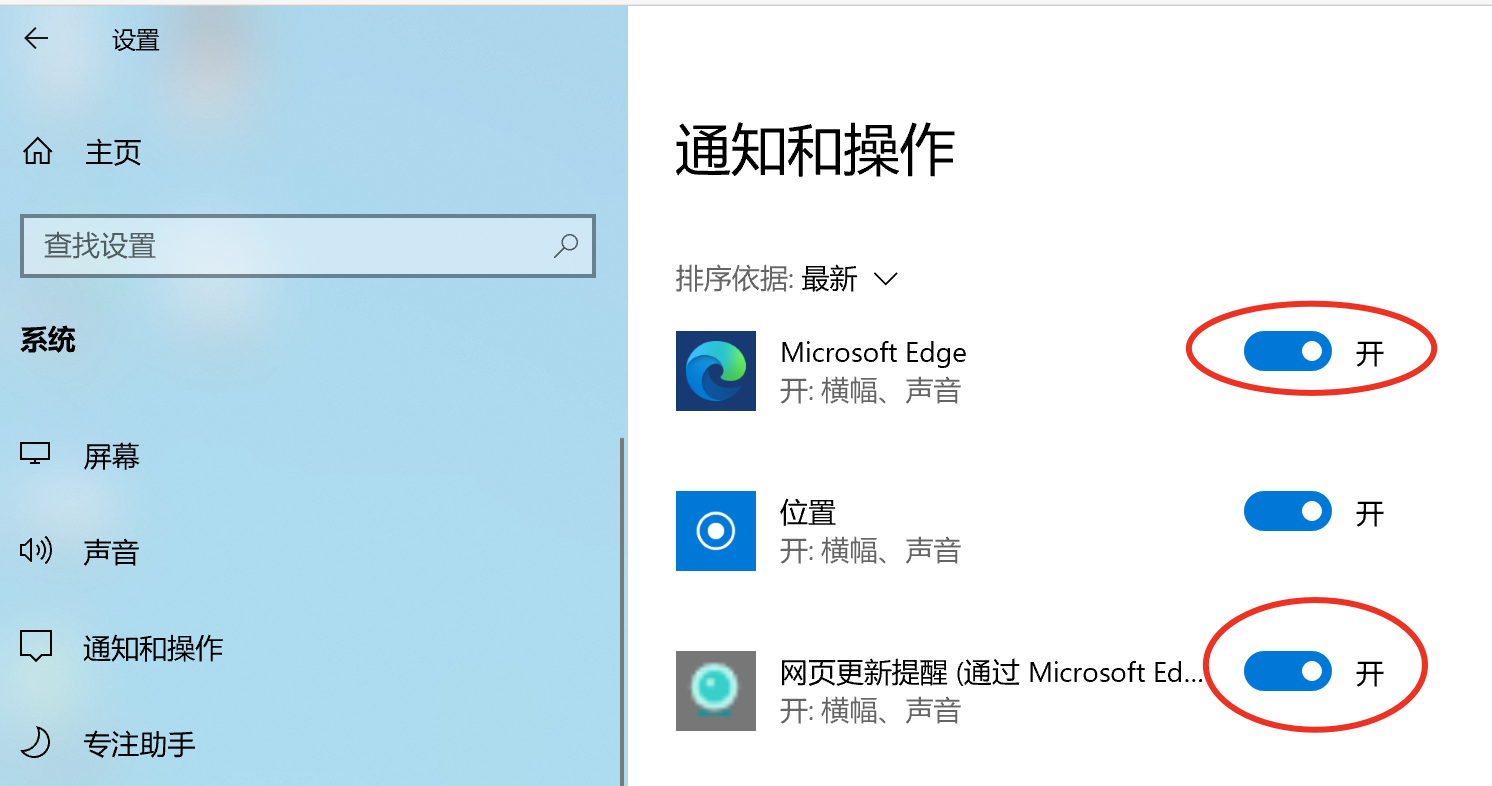
如果桌面通知被禁用了,可以打开chrome://settings/content/siteDetails?site=chrome-extension://fipadnnmmoiomfllhbbnhjnghopkgfpb页面,通知->允许
想要熟练掌握正则表达式非常困难,这是一个高阶程序员应该具备的素养,足以写成一本很厚的书。 但请不要慌,作为资深小白用户想要用明白「网页更新提醒」的正则其实不难,下面我把常用的套路列一下您就明白了。
比如想忽略12分钟前这样的时间变动,这时候就不能用简单的\d+匹配,因为\d+匹配的数字,如果内容中包含数字也会被匹配,所以这种情况需要增加限定词,再把12换成\d+即可,最终的正则:\d+分钟前。
同理,想忽略12件这样的库存变动,可以使用\d+件。
那如果我们想要忽略的内容本省就是纯数字怎么办呢?
比如,想要忽略评论/点赞/浏览量的变化,注意看咱们之前的示例正则后面加了一个$,这个就表示内容的结束符,\d+$就表示匹配以数字结尾的内容,这样就可以避免内容中间出现数字的时候也被匹配。
同理,想要匹配以数字开头则使用^符号,^\d+就表示匹配以数字开通的内容,$\d+$表示纯数字。
以上就是最常用的几种情况,其实就一个数字通配符\d+和^、$限定符。
- 列表页右上角勾选「文本对比」
- 展开任务的更新历史,查看更新的内容(会高亮,如下图所示)

- 如果更新的内容是不关心的,可以通过排除规则进行排除,这个时候只需要负责更新的内容,然后将数字改成
\d+即可,其他内容保留
预处理是比较高级的功能,几乎无所不能,理论上只要是网页就没有做不到的,防刷机制除外。
- 请优先使用可视化预处理(免费),支持基本的模拟输入、选中、点击、滚动、延时等操作。可视化预处理的关键是选择器的获取,模式是通过点击,程序自动获取,但这样并不能百分之百准确,设置号以后点击底部的测试实际验证一下。如果不生效,大概率是选择器不正确,请参看获取选择器
- 如果可视化预处理解决不了,可以联系作者进行代码定制(收费)
就是在检测开始之前,先执行一段自定义的JS脚本,用于页面需要一些操作或者整理以后才能执行检测的场景。
「网页更新提醒」的原理是,定时获取圈选区域的DOM节点文本内容,与上一次的内容进行对比,预处理脚本就是在插件提取内容之前执行的代码。
相当于当次检测的节点控制权完全开放给了使用者,使用者可以自己决定节点的内容,从而决定插件是否能够检测到更新,可以说无所不能。
- 场景①,页面需要先设置过滤条件,然后点击查询才能看到数据,可以使用预处理脚本自动完成
- 场景②,检测的区域没有文字,只有链接或者图片地址会变更,可以通过预处理脚本将链接或者图片地址提取出来插入到监控的区域
- 场景③,页面需要检测的变更条件非常复杂,用匹配/排除规则难以准确界定的场景
- 场景④,页面自动化测试,可以自己编写代码模拟操作并检测操作结果是否符合预期
- 场景N。。。
function _beforeExtract(id, data) {
/*设置输入框数值*/
document.querySelector('.ipt').value = 100;
/*点击按钮*/
document.querySelector('.btn').click();
/*支持异步/延时回调*/
setTimeout(function() {
_callback(id, data);
}, 1000);
}
- 这里
function beforeExtract(id, data) {_callback(id, data);}是固定格式,不要改动 - ID: 是一个标识,代码回调映射,编写脚本不用关心
- data: 是监控任务数据,完整的结构如下:
{
selectors: [
{type: 'xpath', selector: '//UL[1]'}
]
}
插件在检测到更新或者异常的时候,默认是会推送通知的,当然也有选项可以设置不推送。 通知前预处理,可以做更多的个性化配置,使用场景包括:
- 场景①,当检测到异常以后,并不是不推送而是只给特定的人推送
- 场景②,插件的推送内容是程序内定的,可以通过预处理脚本实现推送内容的个性化定制
UID_xxx_N这个用户推送消息,根据盈亏比例显示个性化的推送标题和摘要
function _beforeNotify(id, data) {
var pre = parseFloat(data.preData.text);
var cur = parseFloat(data.curData.text);
var diff = cur - pre;
if (/重新框选/.test(data.text)) {
data.config.webhook = "UID_xxx_N";
} else {
var text = "盈亏比例为:" + ((cur - pre).toFixed(2) / 80).toFixed(4) + "%";
data.text = text;
if (cur > pre) {
data.config.title = "枭龙一号开单了,本单为盈利单!";
} else {
data.config.title = "枭龙一号开单了,本单为亏损单";
}
}
_callback(id, data);
}
- data: 是通知需要的数据,完整的结构如下:
{
text: '消息推送文本内容',
html: '消息详情html代码',
ignored: false, // 是否忽略本次通知
config: {
title: '监控任务标题',
url: '监控任务的url地址',
emails: '通知邮箱',
webhook: '微信UID或者webhook地址'
},
preData: {
text: '上一次检测到的文本内容',
html: '上一次检测到的HTML片段'
},
curData: {
text: '当前检测到的文本内容',
html: '上一次检测到的HTML片段'
},
}
我们可以通过data变量获取对应的数据,也可以动态修改这些字段,达到修改通知内容目的
代码在一个沙盒页面运行,可以访问DOM接口和操作DOM!
注意,这是模板消息,只能修改以上这些字段,其他字段的修改没有意义
检测到更新后,处理进行通知,还可以通过预处理脚本进行进一步的自动化处理。
- 场景①,检测到更新以后,自动点击按钮完成审批/跳转等动作
- 场景②,检测到更新以后,自动下单
- 场景③,检测到更新以后,自动打开其他页面
- 场景N。。。
function _afterUpdate(id, data) {
/*点击按钮*/
document.querySelector('.btn').click();
/*支持异步/延时回调*/
setTimeout(function() {
_callback(id, data);
}, 1000);
}
- data: 是监控任务数据,完整的结构如下:
{
title: '监控任务标题',
url: '监控任务的url地址',
emails: '通知邮箱',
webhook: '微信UID或者webhook地址',
selectors: [
{type: 'xpath', selector: '//UL[1]'}
]
}
每个任务可以设置一个定时任务,在固定的时间点发送一个通知。
通知的内容是可以通过Javascript脚本进行定制的,原则上您可以定制任意的富文本内容(表格、列表等等)。
function schedule(id, data) {
var text = data.list.map(function(item) {
return item.text;
}).join("\n");
var html = data.list.map(function(item) {
return item.html;
}).join("\n");
/*设置报告标题*/
data.config.title="这是日报";
/*设置文本摘要*/
data.text = text;
/*设置通知详情富文本*/
data.html = html;
_callback(id, data);
}
- data: 是通知需要的数据,完整的结构如下:
{
text: '发送消息的文本摘要,需要脚本设置',
html: '发送消息详情html代码,需要脚本设置',
ignored: false, // 是否忽略本次通知
config: {
title: '监控任务标题',
url: '监控任务的url地址',
emails: '通知邮箱',
webhook: '微信UID或者webhook地址'
},
list: [ // 第一条是最新的内容
{html: '每次监控提取的HTML片段', text: 每次监控提取的文本内容},
{html: '每次监控提取的HTML片段', text: 每次监控提取的文本内容}
]
}